TensorFlow Serving is a flexible, high-performance serving system for machine learning models, designed for production environments. TensorFlow Serving makes it easy to deploy new algorithms and experiments, while keeping the same server architecture and APIs. TensorFlow Serving provides out-of-the-box integration with TensorFlow models, but can be easily extended to serve other types of models also.
Serving machine learning models quickly and easily is one of the key challenges when moving from experimentation into production. Serving machine learning models is the process of taking a trained model and making it available to serve prediction requests. When serving in production, you want to make sure your environment is reproducible, enforces isolation, and is secure. To this end, one of the easiest ways to serve machine learning models is by using TensorFlow Serving with Docker.
Docker is a tool that packages software into units called containers that include everything needed to run the software.The documentation is very comprehensive and I encourage you to check it for the details.
TF Serving Architecture

- A Source plugin creates a Loader for a specific version. The Loader contains whatever metadata it needs to load the Servable.
- The Source uses a callback to notify the Manager of the Aspired Version.
- The Manager applies the configured Version Policy to determine the next action to take, which could be to unload a previously loaded version or to load the new version.
- If the Manager determines that it’s safe, it gives the Loader the required resources and tells the Loader to load the new version.
- Clients ask the Manager for the Servable, either specifying a version explicitly or just requesting the latest version. The Manager returns a handle for the Servable.
- Let say a Source represents a TensorFlow graph with frequently updated model weights. The weights are stored in a file on disk. The Source detects a new version of the model weights. It creates a Loader that contains a pointer to - the model data on disk.
- The Source notifies the Dynamic Manager of the Aspired Version.
- The Dynamic Manager applies the Version Policy and decides to load the new version.
- The Dynamic Manager tells the Loader that there is enough memory. The Loader instantiates the TensorFlow graph with the new weights.
- A client requests a handle to the latest version of the model, and the Dynamic Manager returns a handle to the new version of the Servable.
NOTE: For more details follow, https://www.tensorflow.org/serving/overview
Export SavedModel format for ML models
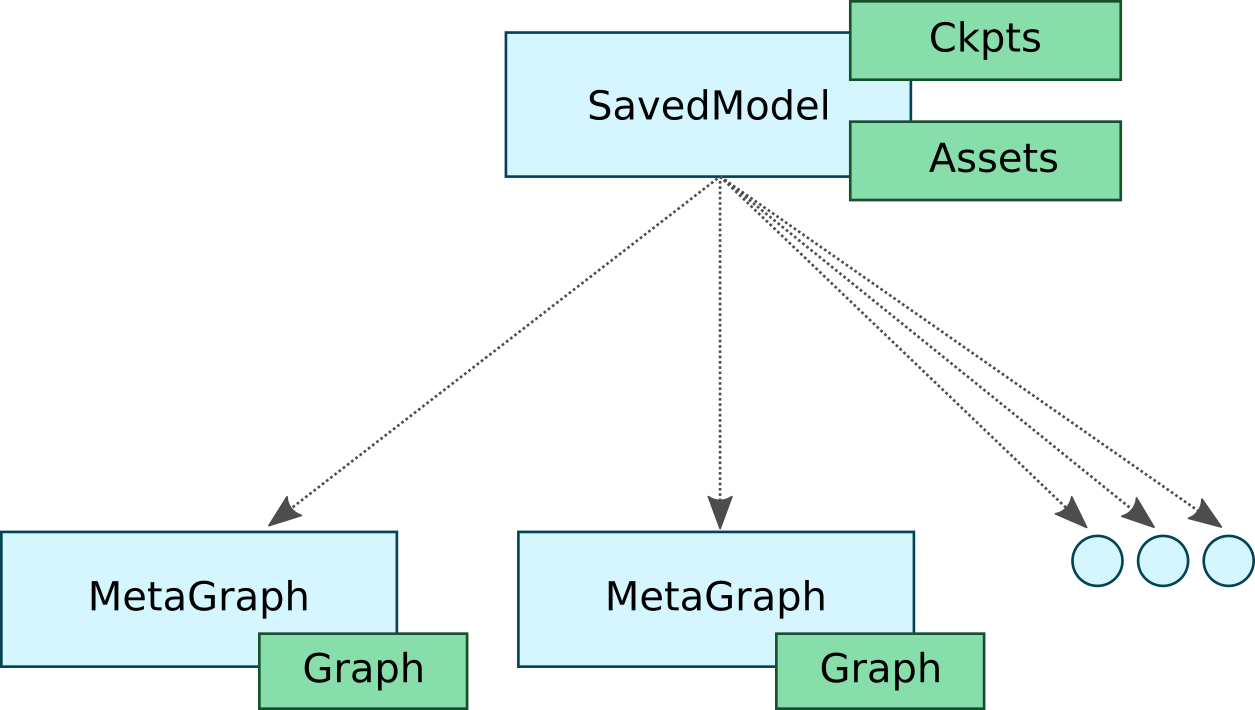
TensorFlow Serving uses the SavedModel format for its ML models. A SavedModel is a language-neutral, recoverable, hermetic serialization format that enables higher-level systems and tools to produce, consume, and transform TensorFlow models.
tf.saved_model.builder provides a low-level api used to create a SavedModel. The tf.saved_model.builder.SavedModelBuilder class provides functionality to save multiple MetaGraphDefs. A MetaGraph is a dataflow graph, plus its associated variables, assets, and signatures. A MetaGraphDef is the protocol buffer representation of a MetaGraph. A signature is the set of inputs to and outputs from a graph.
If assets need to be saved and written or copied to disk, they can be provided when the first MetaGraphDef is added. If multiple MetaGraphDefs are associated with an asset of the same name, only the first version is retained.
Each MetaGraphDef added to the SavedModel must be annotated with user-specified tags. The tags provide a means to identify the specific MetaGraphDef to load and restore, along with the shared set of variables and assets. These tags typically annotate a MetaGraphDef with its functionality (for example, serving or training), and optionally with hardware-specific aspects (for example, GPU).
NOTE: For more details, please follow https://www.tensorflow.org/serving/signature_defs to understand the concept of signature_defs while exporting savedmodel format for TF serving.
Using TF Serving with Docker
Once you have exported the saved model format for your ML models. You can deploy it using TensorFlow Serving. And one of the easiest ways to get started using TensorFlow Serving is with Docker. General installation instructions are on the Docker site, but we give some quick links here:
- Docker for macOS
- Docker for Windows for Windows 10 Pro or later
- Docker for Linux
To serve saved model using Docker, follow the below steps:
Pulling the Serving Image
Once you have Docker installed, you can pull the latest TensorFlow Serving docker image by running:
# For CPU
$ docker pull tensorflow/serving
# For GPU
$ docker pull tensorflow/serving:latest-gpu
NOTE: This will pull down an minimal Docker image with TensorFlow Serving installed. See the Docker Hub tensorflow/serving repo for other versions of images you can pull.
Running a Serving Image
To run the TF serving image, you can do it on Google Cloud VM Instances by running the Instance via ssh or do it locally.
Run the docker container for gRPC API call or REST API call
# For gRPC API call at 8500 and REST API call at 8501 run the following (on CPU)
$ docker run -p 8500:8500 -p 8501:8501 \
--mount type=bind,source=<export_saved_model_path>,target=/models/my_model \
-e MODEL_NAME=my_model -t tensorflow/serving &
# For gRPC API call at 8500 and REST API call at 8501 run the following (on GPU)
$ docker run --runtime=nvidia -p 8500:8500 -p 8501:8501 \
--mount type=bind,source=<export_saved_model_path>,target=/models/my_model \
-e MODEL_NAME=my_model -t tensorflow/serving:latest-gpu &
Breaking down the command line arguments,
-p 8500:8500= Publishing the container’s port 8500 (where TF Serving responds to gRPC API requests) to the host’s port 8500
-p 8501:8501= Publishing the container’s port 8501 (where TF Serving responds to REST API requests) to the host’s port 8501
–mount type=bind,source=export_saved_model_path,target=/models/my_model= Mounting the host’s local directory (export_saved_model_path) on the container (/models/my_model) so TF Serving can read the model from inside the container.
-e MODEL_NAME=my_model= Telling TensorFlow Serving to load the model named “my_model”
-t tensorflow/serving= Running a Docker container based on the serving image “tensorflow/serving”
This will run the docker container and launch the TensorFlow Serving Model Server, bind the gRPC API port 8500, or REST API port 8501 and map our desired model from our host to where models are expected in the container. We also pass the name of the model as an environment variable, which will be important when we query the model.
Internally, Running one of the above command to run the docker container will result in running TF serving Model Server. This will run in the container:
$ tensorflow_model_server --port=8500 --rest_api_port=8501 --model_name=my_model --model_base_path=/models/my_model
Also, In case you wanted to serve a savedmodel directly from a Google Cloud Storage bucket. Run the following command using same docker image
# For CPU
$ docker run -p 8500:8500 -p 8501:8501 -e MODEL_BASE_PATH=gs://mybucket/savedmodel -e MODEL_NAME=my_model -t tensorflow/serving &
# For GPU
$ docker run -p 8500:8500 -p 8501:8501 -e MODEL_BASE_PATH=gs://mybucket/savedmodel -e MODEL_NAME=my_model -t tensorflow/serving:latest-gpu &
Thanks for reading and see you on the next one!
License: CC-BY