Abstractive Speech Summarization is a task in which, the goal is to generate an abstractive summary from the audio dialogue transcript. As we know that when we talk about summarization, there are two ways i.e Extractive Summarization in which idea is to identify important sections of the audio transcript with respect to each speaker and generating them verbatim producing a subset of the sentences from the original text; while in Abstractive Summarization, idea is to generate a short and concise summary that captures the salient ideas of the source text. The generated summaries potentially contain new phrases and sentences that may not appear in the source text. So abstractive summarization is more advanced as well as feels more human-like.
Problem Definition
Let’s now deep dive into problem definition in detail:
Given audio among multiple speakers, the goal is to generate a domain-adapted abstractive summary such that it should be concise and should capture the important facts corresponding to each speaker in the call audio.
Mathematically, we can formulate the problem as follows.
The input to our AI system consists of audio transcripts X with S unique speakers and we have N meetings in total. So, the transcripts are $X = {X_1, X_2, …X_N}$. Here each transcript consists of multiple turns, where each turn is the utterance of a speaker.
Thus, $X_i = {(s_1, u_1),(s_2, u_2), …,(s_{L_i}, u_{L_i})}$, where $s_j ∈ S, 1 ≤ j ≤ L_i$, is a speaker and $u_j = (w_1, …, w_{l_j})$ is the tokenized utterance for speaker $s_j$.
And For each audio transcript $X_{i}$, we have the following labels:
a) Human-labelled speaker tag for each speaker utterances of the $i^{th}$ meeting as $T_i$, $T_i = {(s_1, u_1, t_1),(s_2, u_2, t_2), …,(s_{L_i}, u_{L_i}, t_{L_i})}$, where $t_j ∈$ {Agent, Customer}, $1 ≤ j ≤ L_i$ is a speaker utterance being labelled as either agent or customer Thus, $X_i = {(s_1, u_1),(s_2, u_2), …,(s_{L_i}, u_{L_i})}$, where $s_j ∈ S, 1 ≤ j ≤ L_i$, is a speaker and $u_j = (w_1, …, w_{l_j})$ is the tokenized utterance for speaker $s_j$.
d) Human-labelled category of the $i^{th}$ meeting as $c_i$, $C$ = {$c_1, c_2…c_K$}, where $c_i ∈ C$, $K$ = Total number of categories And For each audio transcript $X_{i}$, we have the following labels:
c) Human-marked important/unimportant utterances for each speaker of the $i^{th}$ meeting as $I_i$, $I_i = {(s_1, u_1, z_1),(s_2, u_2, z_2), …,(s_{L_i}, u_{L_i}, z_{L_i})}$, where $z_j ∈$ {$0,1$}, $1 ≤ j ≤ L_i$ is a speaker utterance being marked as important or not, $0$ = UnImportant, $1$ = Important (Optional)
d) Human-labelled Summary of $i^{th}$ meeting as $Y_i$ for both the speakers i.e $Y_i =$ {$Y_{i_A}, Y_{i_C}$}, where $Y_{i_A} = (w_1^{\prime}, …, w_A^{\prime})$ is a sequence of tokens for agent and $Y_{i_C} = (w_1^{\prime\prime}, …, w_C^{\prime\prime})$ is a sequence of tokens for customer
How its helpful ?
There are many scenarios like meetings, interviews, etc. where dialogue summarization can be helpful but one such important use case is helping Customers Service.
As we know that customer support is a crucial part of every industry. And customer service interaction is also a common form of dialogue, which contains questions of the user and solutions of the agent. So, an AI-powered solution can boost service efficiency by automatically creating summaries that would capture important facts.
Often in Travel and Hospitality industries, Guest Relations department receives a large number of calls from customers asking queries regarding booking, cancellations, billing etc. and a team of agents is expected to address the customer queries and take notes from the conversation with the customer.
This manual process of taking notes after the call takes up a lot of time of the Guest Relations agents and the accuracy of the same is also quite low. There is also a factor of subjectivity that comes in.
These notes by agent gathers important facts like check-In date, check-Out date, booking amount, customer sentiment, hotel location, hotel brand etc. which can be further used for analysis to get insights like % of positive customer sentiment in the call, % of hotel brand usually booked by customer etc. on weekly or monthly basis
AI powered solution can be helpful to either automate this process or assist the agent by generating a agent and customer summary that summarizes above important facts immediately as soon as the call ends.
Challenges
Now, that you have understanding of how this problem is kind of a big deal. But when we started working on this usecase, one thing was sure that we can’t just directly use some blackbox model to generate these summaries. Below are some of the important challenges that our solution tries to address to some extent
Long nature of transcripts: Since, meeting call transcripts are always long which means that usual conversation would contain around 2000-4000 tokens. So, How we can incoperate this long nature of the transcript while designing the architecture.
Hierarchical structure of transcripts: Also, meeting call transcripts always follow a hierarchical structure which means that meeting consists of utterances from different speakers and forms a natural multi-turn hierarchy with each speaker having a fixed style of talking. So, How can we leverage this a hierarchical structure while designing the architecture.
Different Style: Semantic structure and styles of meeting call transcripts are quite different from articles and conversations.
Generative Repetitions: Often generative models have this common problem of repetions due to which it predicted summary contains repetative facts. So, How can we avoid these repetitions.
Generative Hallucinations: Generative models also have a problem of hallucinations due to which it predicted summary contains facts that are not even mentioned in the actual input transcript. So, How can we generate in a controlled manner.
Incorrect Gender: If human-labelled summary contains sentences referring speaker as third person (he or she) then, it can be possible that generated summary would contain wrong gender. So, How do we identify gender of each speaker from the original audio call and incoporate that to correct the gender in final prediction.
Few shot settings: If we don’t have enough human-labelled data. So, how can we make our system learn in few shot settings
Previous Research Work
Most of the early abstractive approaches were based on either sentence compression or templates to generate summaries. But in recent years, we have seen very significant advancements, thanks to the emergence of neural sequence-to-sequence models. Although previously sequence-to-sequence models were based on recurrent neural networks which actually set a good benchmark and was considered as state of the art for a long time but by recently, we found that how using Transformers architecture further pushed this benchmark.
Also initially, the area was mostly concerned with headline generation, followed by multi-sentence summarization on news databases (like CNN/DailyMail corpus). Further improvements include pointer generator networks which learn whether to generate words or to copy them from the source; attention over time; and hybrid learning objectives.
During the early days of the use case, we tried several methods just to check the baseline before we finalized the final solution. Though, these baseline methods were trained on above (CNN/DailyMail corpus) data like pointer generator network which gave poor results and was hallucinating.
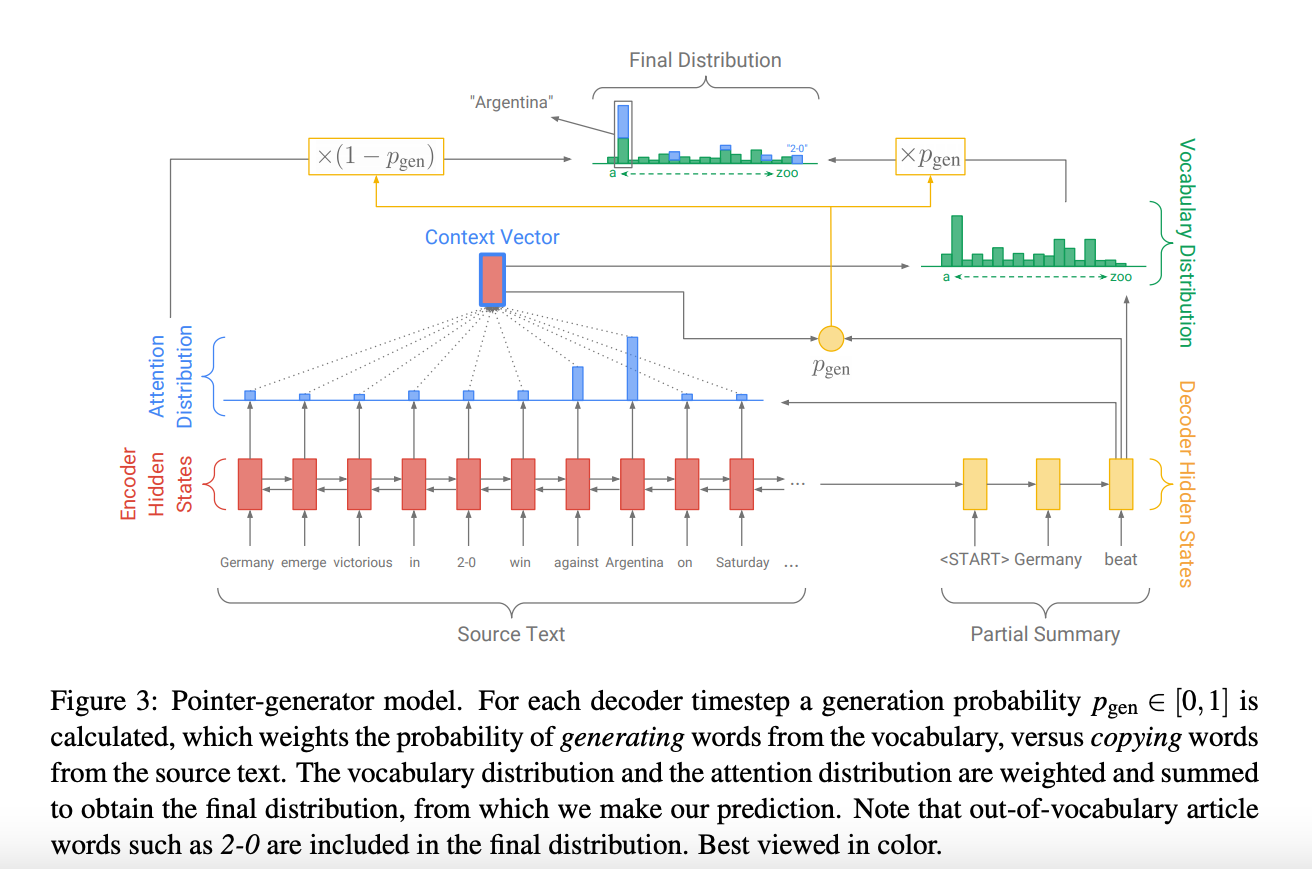
Above Figure-3 is a pointer generator network which is hybrid between baseline (sequence to sequence network with attention) and pointer network as it facilitates copying words from the source text via pointing, which improves accuracy and handling of OOV words, while retaining the ability to generate new words.
a) Attention distribution (over source positions)
\[e_i^j= w^T tanh(W_h h_i + W_s s_j + b_{attn})\]Here, $h_i$ is the encoder states and $s_j$ is the decoder states
\[p^j = softmax(e_j)\]Here, $p^j$ represents the attention probability distribution that $j^{th}$ position in decoder pays to all the moments in encoder (i.e what all encoder moments are given more weightage while decoding for $j^{th}$ position)
b) Vocabulary distribution (generative model)
\[v_j = \sum_{i} p_i^j h_i\]Here, $v_j$ is a context vector for $j^{th}$ position of decoder
\[p_{vocab} = softmax(V'(V[s_j, v_j] + b) + b')\]Here, $p_{vocab}$ is a vocabulary probability distribution for $j^{th}$ position of decoder
c) Copy distribution (over words from source)
\[p_{copy}(w) = \sum_{i:x_i=w} p_i^j\]d) Final distribution
\[p_{final} = p_{gen} p_{vocab} + (1 - p_{gen}) p_{copy}\] \[p_{gen} = \sigma(w_v^T v_j + w_s^T s_j + w_x^T y_{j-1} + b_{gen})\]Here, $p_{gen} ∈ [0,1]$
So, in pointer generator network the final distribution depends on $p_{gen}$ which is used as a soft switch to choose between generating a word from the vocabulary by sampling from $p_{vocab}$, or copying a word from the input sequence (source text) by sampling from the copy distribution $p_{copy}$. Note that in case of OOV token, $p_{vocab}$ will be zero which means the it can copy word from input sequence (source text) and this is how it solves the issue of predicting UNK tokens in the predicted summary.
During training goal is minimize the negative of log likelihood of predicting the summary tokens as following
\[Loss = - 1/J \sum_{j=1}^{j} log p_{final}(y_j)\]Overall pointer generator network showed that its sometimes beneficial to copy from input sequence (source text). Due to this it beat baseline network, but still due to copy distribution summaries would sometimes contain repetitions which was further fixed by coverage mechanism. Please refer to research paper for more details
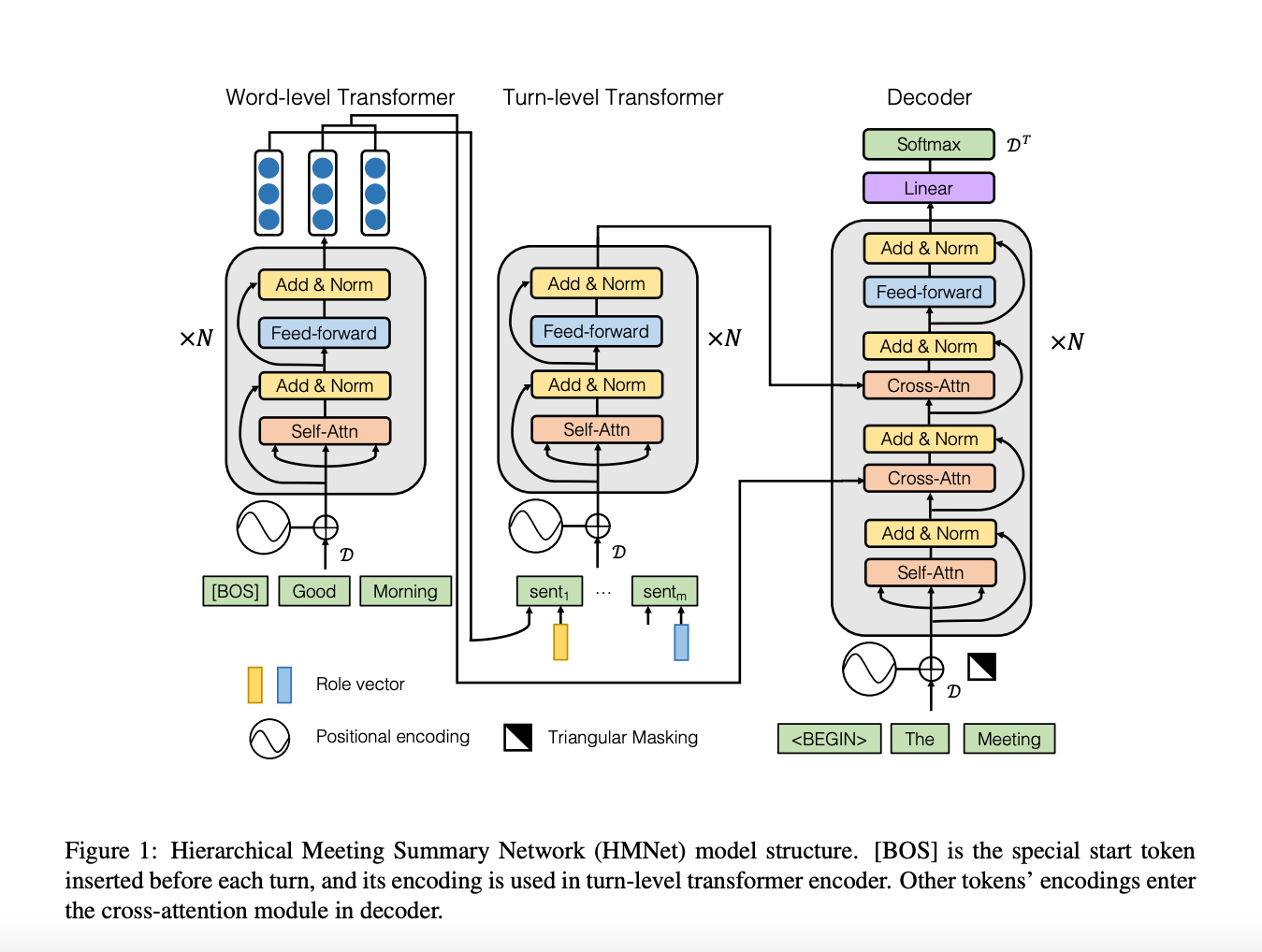
HMNet (Hierarchical Network for Abstractive Meeting Summarization) is a latest work that tries to solve exactly the same problem which we were trying to solve as it is specially for meeting call transcripts and based on state of the art Transformer architecture. It also solves some of the challenges mentioned above.
Above Figure-1 is HMNet is based on the encoder-decoder transformer structure, and its goal is to maximize the conditional probability of meeting summary $Y$ given transcript $X$ and network parameters ${θ: P(Y|X; θ)}$.
As we know that the vanilla transformer has the attention mechanism, its computational complexity grows to quadratic as the input length increases. Thus, it struggles to handle very long sequences, e.g 2000-3000 tokens. Also, meeting call transcripts are always long but we can notice that the each transcript comes with a natural multiturn structure with a reasonable number of turns e.g around 100-200 turns. Therefore Therefore, HMNet employ a two-level transformer structure to encode the meeting transcript as follows.
a) Word Level Transformer
The encoder part consists of Word-level Transformer that processes the token sequence of one turn in the meeting. It encode each token in one turn using a trainable embedding matrix $D$. Thus, the $j^{th}$ token in the $i^{th}$ turn, $w_{i,j}$ , is associated with a uniform length vector $D(w_{i,j} ) = g_{i,j}$. To incorporate syntactic and semantic information, we also train two embedding matrices to represent the part-of-speech (POS) and entity (ENT) tags. Therefore, the token $w_{i,j}$ is represented by the vector $x_{i,j} = [g_{i,j}; POS_{i,j}; ENT_{i,j}]$. Note that a special token is added as $w_{i,0}=[BOS]$ before the sequence to represent the beginning of a turn. Then, the output of word-level transformer gives $x_{i,j}$, i.e contextualized representation of $j^{th}$ word in $i^{th}$ turn, where $1 ≤ j ≤ L_i$ and $1 ≤ i ≤ M$, $L_i$ = Number of tokens for $i^{th}$ turn, M = Number of Turns
b) Turn Level Transformer
As we know that the meeting call transcripts have this hierarchical structure such that each participant has different semantic styles and viewpoints e.g., program manager, industrial designer. Therefore, the model has to take the speaker’s information into account while generating summaries. To incorporate the participant’s information, idea is to integrate the speaker role component. So, a trainable matrix is considered as $R$ such that for each role, a vector is trained to represent it as a fixed-length vector $r_p$, $1 ≤ p ≤ P$, where $P$ is the number of roles.
The turn-level transformer processes the information of all M turns in a meeting call transcript. To represent the $i^{th}$ turn, the output embedding of the special token $[BOS]$ from the word-level transformer is used which is concatenated with the role vector of the speaker as $p_i$ for the $i^{th}$ turn. Then, the output of turn-level transformer gives $m_i$ i.e contextualized representation of $i^{th}$ turn, {$m_1, m2, …m_M$}, M = Number of Turns
c) Decoder
The decoder is a transformer to generate the summary tokens. The input to the decoder transformer contains the $k − 1$ previously generated summary tokens ${\hat{y_1} ,…,\hat{y}_{k-1}}$. Each token is represented by a vector using the same embedding matrix $D$ as in the encoder. Also, each decoder transformer block includes two cross-attention layers.
After self-attention, the embeddings first attend with token-level outputs $[x_{i,j}]$ and then with turn-level outputs {$m_1, m2, …m_M$}, each followed by layer-norm. This makes the model attend to different parts of the inputs. Then, the output of decoder gives {$v_1,v2, …,v_{k-1}$} To predict the next token $\hat{y_{k}}$, we reuse the weight of embedding matrix $D$ to decode $v_{k−1}$ into a probability distribution over the vocabulary:
\[P(\hat{y}_{k}|\hat{y}_{<k}, X) = softmax(v_{k−1}D^T)\]Finally, during training the goal is to minimize the negative of log likelihood of predicting the summary tokens as following
\[Loss(θ) = - 1/n \sum_{k=1}^{n} logP(\hat{y}_{k}|\hat{y}_{<k}, X)\]Teacher forcing is used while training decoder i.e the decoder takes ground-truth summary tokens as input. During inference, beam search method is used to select the best candidate. The search starts with the special token $[BEGIN]$ and a commonly used trigram blocking search is followed, if a candidate word would create a trigram that already exists in the previously generated sequence of the beam then forcibly set the word’s probability to 0. Finally, the summary with the highest average log-likelihood per token is selected.
Overall HMNet set a new benchmark on AMI and ICSI datasets with the generated summary. Please refer to research paper for more details
References
Abigail See, Peter J. Liu, Christopher D. Manning. 2017. Get To The Point: Summarization with Pointer-Generator Networks
Chenguang Zhu, Ruochen Xu, Michael Zeng, Xuedong Huang. 2020. A Hierarchical Network for Abstractive audio Summarization with Cross-Domain Pretraining.
Chunyi Liu, Peng Wang, Jiang Xu, Zang Li, Jieping Ye. 2019. Automatic Dialogue Summary Generation for Customer Service
Yulong Chen , Yang Liu, Liang Chen, Yue Zhang. 2021. DIALOGSUM: A Real-Life Scenario Dialogue Summarization Dataset
Chenguang Zhu , Yang Liu , Jie Mei, Michael Zeng. 2021. MEDIASUM: A Large-scale Media Interview Dataset for Dialogue
Chih-Wen Goo, Yun-Nung Chen. 2018. Abstractive Dialogue Summarization with Sentence-Gated Modeling Optimized by Dialogue Acts